Стандарты написания HTML и определение типа документа DOCTYPE. Урок 5.
Спецификации HTML и их объявления с помощью DOCTYPE
Я часто в своих уроках делал такие утверждения, как – «один тэг должен располагаться внутри другого», «у тэга img должен быть атрибут src», «сначала идёт тэг head, а потом body» и так далее. Но я ведь не придумывал всё это на лету, - а руководствовался неким регламентом, автором которого является организация, которая собственно придумывает и утверждает все стандарты, - называется она W3C (Консорциум Всемирной Паутины). Раньше я об этом не упоминал, но стандартов написания HTML существует несколько. И у каждого из них есть свои особенности и правила написания. Связано это с тем, что HTML не стоит на месте, а постоянно развивается.
И если в ранних версиях стандарта, когда не было технологии CSS, с помощью языка разметки можно было создавать как структуру, так и дизайн, то сейчас тенденция намечается совершенно иная, - HTML стал больше ассоциироваться со структурой (фундаментом и кирпичиками), на которых и держится дизайн. CSS здесь - это нечто вроде декоративного элемента, задающего оформительский вид – аналог плитки и обоев, если рассматривать создание сайта как строительство дома. В связи с этим, в новых стандартах HTML, некоторые тэги и атрибуты, отвечающие за дизайн, - объявлены нежелательными (deprecated). То есть, текущая спецификация стандарта их поддерживает, но уже в следующей поддержка будет прекращена.
Есть ещё более строгий стандарт, который называется XHTML, - он так вообще не терпит вольностей с кодом и не прощает грубые ошибки. Самый новый на данный момент – это HTML 5, за ним будущее, поэтому в дальнейшем мы и будем на него равняться.
С этим вроде бы всё должно быть понятно, - есть несколько стандартов и замечательно. Но вместе с тем, есть браузеры, в задачу которых входит обработка HTML кода, и браузер не всегда может понять, в соответствии с каким стандартом мы пишем и что конкретно имел ввиду пользователь и соответственно как этот код нужно отображать. То ли мы используем переходный HTML (Transitional), и браузер прощает нам многие ошибки, используя «щадящий режим», то ли мы используем режим строгой совместимости XHTML и ошибки нужно обрабатывать со всей строгостью. Иными словами, перед браузером стоит сложная задача.
Как поступает браузер в таком случае? Он отображает код в режиме обратной совместимости, - все явные и неявные ошибки в коде он сглаживает и пытается максимально предугадать что же имел ввиду пользователь. Но тут есть некоторые очевидные недостатки: во-первых, браузер не может знать, что же имел ввиду человек изначально. Во-вторых, у каждого браузера этот режим совместимости может срабатывать по-разному. Что в итоге имеем? Есть код и нету регламента, - на практике это означает что одна и та же разметка, в режиме совместимости, браузером будет отображаться по-разному. Следовательно, нам нужен какой-то способ дать браузеру знать, какой же стандарт мы собираемся использовать.
И такой способ действительно есть, называется он – добавлением определения типа документа.
В коде объявление типа задаётся вот так:
<!DOCTYPE html>
Данной строкой мы даём браузеру понять, что на нашей страничке будет использоваться режим HTML 5. Вставляется это строка в самом начале документа. Попробуйте проделать это в вашем тестовом HTML файле.
На многих сайтах ещё можно встретить такую строчку:
<!DOCTYPE html PUBLIC "- //WЗC//DTD НТМL 4.01 Transitional//EN" "http: ./www.w3.org/TR/html4/loose.dtd">
Данная строка означает, что используется стандарт HTML 4.01. Но мы не будем его использовать, поскольку он устаревший. Но тем не менее, он тоже нередко встречается и знать о нём стоит.
Теперь объясню, зачем всё это нужно. Данной строкой мы задали некий стандарт, в соответствии с которым браузер должен выводить наш документ в окно браузера. На практике это означает, что наш HTML код будет более-менее одинаково отображаться во всех браузерах. Всего этого было бы невозможно достичь, если бы мы работали в режиме обратной совместимости (quirksmode), который включается если объявление типа документа пропускать. В моей практике, связанной с вёрсткой страниц, это было действительно важно. Потому что, объявление DOCTYPE, в итоге решило проблему одинакового отображения страницы во всех браузерах.
Валидация документа.
Разумеется, если мы хотим проверить себя на предмет того, не ошиблись ли мы где-либо в соблюдении тех или иных стандартов, нам не обязательно делать это, изучая наш код глазами. Всё это уже давно автоматизировано, ведь есть средство проверки, благодаря которому мы можем узнать, не допустили ли мы каких-то явных ошибок в своей разметке.
Для этого достаточно перейти по ссылке – http://validator.w3.org
На этой страничке мы сможем найти несколько способов проверки:
- Указать реально существующий сайт.
- Загрузить файл с вашего компьютера.
- Вставить непосредственно сам код, который вы хотите проверить, в соответствующее поле.
В нашем случае, скорее всего подойдёт второй или третий вариант.
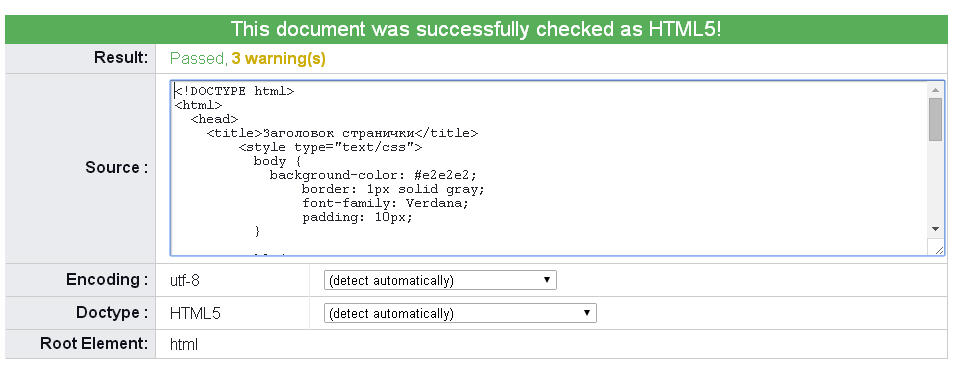
Я лично использовал третий способ. Мой документ валидацию прошёл успешно, о чём и отрапортовала программа строкой This document was successfully checked as HTML5! на зелёном фоне.
При другом исходе, – надпись будет отображена на красном фоне. Это будет означать, что где-то мы допустили ошибку. Собственно, сама программа укажет где и на какой строке мы ошиблись и в чём именно, правда на английском языке.
Но в моём случае, программа, помимо того, что объявила о том, что валидация прошла успешно, также выдала мне три предупреждения:
1. Using experimental feature: HTML5 Conformance Checker
Дело в том, что стандарт HTML 5 формально ещё не окончательно утверждён консорциумом, который продолжает в него внедрять новые полезные фишки. Но на практике – всё большее и большее количество разработчиков начинают его использовать уже сейчас, чтобы быть готовым к завтрашнему дню.
2. No Character encoding declared at document level
В документе не сказано ни слова о том, какая кодировка используется. Действительно, ведь мы её не указали явно, а значит не факт, что вместо того, чтобы отобразить русские буквы, - браузер отобразит какие-то китайские иероглифы. Происходит так потому, что браузер при отображении документа руководствуется какой-то кодовой таблицей (то есть кодировкой), где каждой букве назначается соответствующий ей кодовый символ. Но то, что в одной кодировке одно число означает одну букву, то в другой – может означать какой-то японский иероглиф. Следовательно, браузеру нужно сообщить, какую кодировку использовать. Если этого не сделать, то браузер всё равно попробует её угадать сам. Но гарантий того, что он сделает это правильно, - совершенно нет.
3. Using Direct Input mode: UTF-8 character encoding assumed
Программа предупреждает, что она по умолчанию использует utf-8.
Что же, тогда не остаётся ничего, кроме как объявить используемую нами кодировку. Делается это вот таким образом:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
Сама строка должна быть вложена в элемент head.
Тэг meta относится к разряду служебных тэгов, он как бы сообщает, что есть какая-то информация о странице, которую мы хотим сообщить браузеру. У него, как и у любого другого тэга, есть атрибуты:
http-equiv– это атрибут, в значении которого мы указываем название заголовка.
content– атрибут, в качестве значения которого мы указываем значение заголовка, в данном случае значение заголовка Content-type.
Давайте теперь рассмотрим значения атрибутов, которые только что указали:
Content-Type– говорим браузеру о том, что будем сообщать о том, какой тип у нашего документа. А также, какая кодировка в нём используется.
text/html; charset=utf-8 – документ типа text/html, который использует кодировку utf-8.
Попробуйте провести валидацию страницы ещё раз. Предупреждающих сообщений теперь быть не должно. Но они могут всё равно остаться, но уже по другой причине. К примеру:
1. Вы используете в своём документе изображения, и у вас в тэге img не задан атрибут alt.
2. В элемент body вложен строчный элемент. В соответствии со спецификацией, в элементе bodyдолжны быть только блочные элементы. А уже в них, могут находиться строчные.
Примеров ошибок может быть много, но упомянуть о всех, в рамках одной статьи проблематично. Однако, если во время валидации, вы встретили какую-то иную ошибку, то напишите о ней в комментариях, - будем разбираться вместе.